
Disegnare i volti con il Generative Adversarial Network, è un nuovo modo di fare arte?
di Federica Spagnoli, ISIA RM, DiCultHer
Abstract
In the last few years Artificial Intelligence has found application in numerous functional areas of everyday life. History show us how art and technology have often been needful for each other: technology influences not only artistic creation, by establishing the possibilities of expression among artists, but also leads to the transition to different functions of art, also changing the way it’s used.
Today’s reality presents us with innovations and works by artists/scientists who lead us to new languages, sometimes surprising or far from the concept of work of art traditionally understood.
Now as then, reality evolves faster than rules and the artist, the collector or the gallerist must be compared to works made by software, to new methods of authentication of works of art.
An example of this is the Bellamy family portraits, made with an algorithm and sold by christie’s for $432,000: to do this, specific algorithms were used, which were given more than 15000 portraits from the Renaissance and modern era in order to be able to identify the variables and constants present in the reference database and generate a series of family portraits.
With the support of deep learning systems, artificial intelligence is able to understand and translate hundreds of different languages, recognise objects, people or animals within images.
Soon, however, artificial intelligence algorithms could acquire a new feature, until now exclusive to human intelligence: creativity. This would be due to the so-called Generative Adversarial Network: a class of algorithms that implements not one but two neural networks that collide with each other in order to create as well as learn.
Un binomio senza tempo
Negli ultimi anni l’intelligenza artificiale (AI secondo l’acronimo inglese) ha trovato applicazione in numerosi settori funzionali della vita quotidiana, ma in questo articolo ci soffermeremo sull’applicazione dell’AI nell’arte e nella cultura. La storia ci dimostra che l’arte e la tecnologia sono spesso state indispensabili l’una per l’altra: da sempre gli artisti si sono basati sulle conoscenze tecnologiche e sull’ingegno per trovare i materiali e gli strumenti adatti per esprimere al meglio i propri sogni, pensieri, visioni o credenze e ogni opera d’arte è determinata soprattutto dai materiali a disposizione dell’artista e dall’abilità di questi nel manipolarli. La tecnologia non solo influenza la creazione artistica condizionando le possibilità di espressione degli artisti, ma determina l’evoluzione del ruolo dell’arte nella società modificandone anche le modalità di fruizione.
La tecnologia ha cominciato a costruire un legame con l’arte fin dagli inizi del Quattrocento, quando l’artista-scienziato Flippo Brunelleschi inventò la prospettiva segnando così il passaggio dal Medioevo al Rinascimento. Questo inscindibile rapporto lo si può vedere anche nella pittura impressionista del 1860, nata grazie alle nuove scoperte scientifiche e soluzioni tecniche.
La fotografia, tecnologia dell’immagine per eccellenza, ha le sue origini nella “camera oscura leonardiana”, largamente usata da artisti come Vermeer, Canaletto e Bellotto. E qui spicchiamo un volo deciso fino all’800 quando, allo studio per il perfezionamento della camera oscura si è affiancato lo studio degli elementi chimici fotosensibili, quali i sali d’argento. Stava nascendo la fotografia (dal greco fotòs, luce + grafìa, scrittura), e tutta l’arte dovette ripensarsi dal profondo, quasi da zero. Fu Hyppolite Bayard, nel 1840, a servirsi della tecnologia per inventare la fotografia con il metodo della stampa positiva diretta.
Nel 1919, Walter Gropius, fonda la scuola che cambiò per sempre il rapporto tra arte, design e tecnica. Dalla pittura alla grafica, all’architettura e al design: non c’è quasi nessun campo artistico che non venne influenzato dall’esperienza della scuola Bauhaus. Anche il cinema fu fortemente influenzato dalla tecnologia, l’ausilio della macchina divenne sempre più preponderante fino a dar vita, nel 1931 a film come “Frankestein” di James Whale in cui la tecnologia e la ricerca di un’intelligenza propiziata dalla scienza sono le protagoniste indiscusse. Sarà poi nel 2014 che Jan J. Goddfellow darà vita al lato creativo dell’apprendimento automatico.
L’ausilio della macchina
La realtà di oggi ci pone di fronte ad una ennesima rivoluzione e ad opere realizzate da artisti/scienziati che ci conducono verso nuovi linguaggi, che a volte ci appaiono sconvolgenti e lontani dal concetto di opera d’arte intesa in senso tradizionale.
Oggi come allora, la realtà si evolve più velocemente delle regole e l’artista, il collezionista o il gallerista si trova a confrontarsi con lavori realizzati da software sofisticati e con i nuovi metodi di autenticazione dei capolavori artistici.
Del resto il rapporto tra intelligenza e tecnica da sempre ha affascinato registi, scrittori, artisti. Si pensi solo al mito di Frankenstein [1]e all’anelito dello scienziato alla creazione della vita.
Lev Manovich [2], scrittore statunitense, sottolinea come i primi esperimenti fra arte e AI risalgano agli anni ’60 del Novecento e riguardavano soprattutto il rapporto creativo fra il singolo artista e la sua opera; a partire dagli anni Duemila invece, anche in seguito all’espansione dei Big Data e dell’IoT, questa problematica coinvolgerà milioni di persone e avrà la capacità di influenzare il gusto e le scelte estetiche del pubblico fino a condizionanrne l’immaginario. Oggi, l’impatto dell’AI sull’arte e la cultura si manifesta in due ambiti: produzione di opere d’arte ed eventi culturali, e la valutazione critico estetica di entrambi gli aspetti.

Le prime opere d’arte del sistema GAN, i ritratti della famiglia Belamy
Il ricorso all’IA e agli algoritmi rischia di produrre forme di omologazione ma, come suggerisce lo stesso Manovich, può anche generare una pluralità di espressioni estetiche. Il caso del ritratto di Edmond Belamy [3], realizzato con un algoritmo e venduto da Christie’s per 432.000 dollari rappresenta una grandissima novità, anche perché un’opera di questo genere non era mai stata venduta ad un prezzo così alto.
Si tratta di un’opera d’arte non creata dall’uomo che pone l’accento sul tema del rapporto di operazioni di questo tipo con la creatività artistica, costringendoci a ricordare che forse stiamo proseguendo lungo un cammino tracciato da Marcel Duchamp, da Man Ray, dalla Video Art e dalla Computer Art dei nostri giorni.
In questo caso l’obiettivo è ricollegarsi alla tradizione della grande ritrattistica, imitando la pittura dei secoli passati: per far questo sono stati usati specifici algoritmi, ai quali sono stati “dati in pasto” più di 15.000 ritratti di epoca rinascimentale e moderna. Dopo aver individuato le costanti e le variabili presenti nel database appositamente costruito, il software è stato in grado di generare tutta una serie di ritratti “di famiglia”.
Memories of Paaserby I
Memories of Passersby I [4] è un’opera pionieristica dell’intelligenza artificiale. Il software, completamente autonomo, utilizza un complesso sistema di reti neurali per generare un flusso infinito di ritratti e visioni inquietanti di volti maschili e femminili creati dalla macchina. A differenza delle precedenti installazioni di arte generativa, Memories of Passersby I non contiene un database. È un “cervello AI” sviluppato e addestrato da Mario Klingemann, che crea ritratti innovativi, disegnati pixel per pixel, in tempo reale. Gli output visualizzati sullo schermo non sono combinazioni casuali o programmate di immagini esistenti, ma opere d’arte uniche generate dall’AI. Il cabinet in legno contenente il cervello AI. Memories of Passersby I contiene tutti gli algoritmi e il GAN (Generative Adversarial Networks) necessari per produrre una successione infinita di nuove immagini fintanto che è in esecuzione. Klingemann ha addestrato il suo modello AI utilizzando migliaia di ritratti dal XVII al XIX secolo.

Mario Klingemann, Memories of Passersby I, 2018
Delegare la volontà alla macchina
Il tema dell’autonomia creativa della macchina è molto meno nuovo di quanto si potrebbe pensare: “Oggi si parla sempre dell’arte dell’intelligenza artificiale e in particolare della GAN”, ma in verità questi temi furono affrontati già negli anni Sessanta da Michael Noll [5], che nei Bell Labs fu tra i primissimi a usare calcolatori per produrre immagini che all’epoca era un’idea bizzarra considerato che non esistevano nemmeno gli schermi ed era necessario stampare ogni lavoro. All’epoca l’autore si era comunque posto il problema della creatività della macchina e del bilanciamento tra controllo e caso nella creazione artistica. Nella prima opera creata con il computer – delle linee che uniscono dei punti – Noll inserì nel software un fattore random, lasciando alla macchina un certo margine di libertà nel determinare quali punti unire prima degli altri.
Quindi l’idea di delegare una parte di volontà, diciamo così, alla macchina” era già presente. Lo stesso Mario Klingemann, pur riconoscendo alla macchina un certo grado di creatività, non le attribuisce però una agency. Klingemann afferma infatti di essere lui stesso a “controllare il processo artistico in modo indiretto, addestrando il modello su insiemi di dati selezionati e sugli iper-parametri del modello, e infine operando una selezione, scegliendo tra le migliaia di varianti (…) quella che più mi parla”. Lo strumento potrà avere maggiore o minore autonomia, ma sempre uno strumento rimane.
Il sistema GAN (Generative Adversarial Network)
Grazie al supporto dell’apprendimento automatico e dei sistemi di deep learning, l’intelligenza artificiale è in grado di comprendere e tradurre centinaia e centinaia di lingue differenti; riconoscere oggetti, persone [6] o animali all’interno di immagini; riconoscere (e in alcuni casi prevedere) l’insorgere di malattie anche gravi; fare chiamate per prenotare tavoli o appuntamenti dal parrucchiere e molto altro ancora.
Presto, però, gli algoritmi di intelligenza artificiale potrebbero acquisire una nuova qualità, sinora “esclusiva” dell’intelligenza umana: la creatività. Merito della cosiddetta Rete Antagonista Generativa, o in inglese Generative Adversarial Network (GAN), una classe di algoritmi usati nell’apprendimento automatico non supervisionato, che implementa due reti neurali che si “scontrano” tra loro per creare oltre che apprendere. Al momento i sistemi GAN sono stati usati per:
- realizzazione di immagini da zero [7];
- per il design o l’arredo di interni;
- realizzare modelli grafici in 3D partendo da delle foto;
- migliorare la qualità delle immagini in arrivo dalle stazioni astronomiche.
Nell’assemblare la rete antagonista generativa, le immagini create dal generatore costituiranno l’input del ‘discriminatore’. Quando il discriminatore fornisce la sua valutazione (“reale” o “artificiale”), la confronta con le immagini presenti nei di test per determinare la correttezza del giudizio. Se il giudizio è errato (volto artificiale scambiato per vero), il discriminatore apprenderà dall’errore e migliorerà le risposte successive, mentre se il giudizio è corretto (volto artificiale identificato come tale), il feedback aiuterà il generatore a migliorare le immagini successive. Questo processo [8] continua finché le immagini prodotte dal generatore e i giudizi del discriminatore raggiungeranno un punto di equilibrio. In pratica le due reti neurali competono “addestrandosi” l’un l’altra.
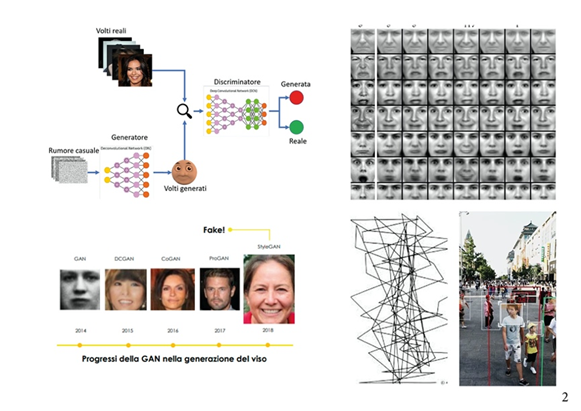
Il compito di una GAN è di generare creazioni proprie, basate su una raccolta di esempi reali, che devono sembrare così vere da rendere difficile immaginare che siano state generate da un computer senza l’intervento di esseri umani.
Il compito della rete generativa è di creare un’imitazione.
La rete è alimentata da una serie di dati e, sulla base di questi dati, è in grado di creare un’immagine. La nuova immagine non sarà quindi un duplicato di uno dei dati di partenza, ma un’opera completamente nuova di natura simile. Lo scopo del discriminatore è verificare se i dati ricevuti siano autentici o falsificati, ma anche quando sono troppo perfetti. Entrambe le reti cercano di svolgere il proprio ruolo in competizione e poiché le due reti neurali si addestrano a vicenda, ci stiamo confrontando con un sistema di deep learning. Gli ingegneri di Nvidia hanno incorporato nel loro lavoro un metodo noto come “trasferimento di stile”, in cui le caratteristiche di un’immagine si fondono con un’altra.
L’applicazione del “trasferimento di stile” ha consentito ai ricercatori di Nvidia di personalizzare i volti a un livello espressivo impressionante: l’immagine sorgente di una persona reale si fonde con le caratteristiche facciali di un’altra persona, i tratti somatici come il colore della pelle e dei capelli si fondono creando quella che sembra essere una persona completamente nuova.
Riprodurre l’espressione
Un team di ricerca della University of Southern California, fra cui anche il prof. Hao Li ha presentato un nuovo framework di deep learning che consente di variare le espressioni di una persona riprodotte su una fotografia, senza confonderne le caratteristiche facciali come farebbe un comune deepfake.
Con il nuovo sistema è possibile prendere la singola foto di un individuo e copiarne l’espressione sulla foto di un’altra persona o di un quadro, mantenendo tutte le caratteristiche dell’immagine di destinazione (identity preservation). Per fare questo si usano due reti: la prima si chiama Landmark Disentanglement Network (LD-Net) e copia l’espressione e le posizioni dei volti [10], mentre l’altra è la Feature Dictionary-based Generative Adversarial Network (FD-GAN) e ha il compito di generare la nuova immagine sulla base di tali caratteristi

Trasferimento di stile: generare i volti
Nuovo framework deep learning per cambiare le espressioni facciali su foto o quadri, studio del team di ricerca della University of Southern California
La rievocazione storica di un ritratto
In questo progetto il team di ricerca ha mirato ad affrontare la conservazione dell’identità nei soggetti esaminati durante una rievocazione storica di un unico ritratto.
Introducono una nuova tecnica che può diversificare espressioni e pose, permettendo di preservare l’identità nella riproposizione del ritratto [11] [12]. Ciò è ottenuto utilizzando una nuova tipologia di rete (LD-Net) che prevede punti di riferimento facciali personalizzati in grado di combinare l’identità dell’immagine di riferimento con le espressioni e le pose di un soggetto diverso.
Come dare un volto alle statue?
Daniel Voshart ha trasformato o restaurato (crepe, nasi, orecchie ecc.) 800 immagini di busti [13] per realizzare i 54 imperatori del Principato (dal 27 a.C. al 285 d.C.). Di alcuni imperatori (delle ultime dinastie, con regni di breve durata) non esistevano busti scultorei sopravvissuti. Per questi personaggi Voshart ha utilizzato più ritratti presenti sulle monete, l’albero genealogico e i luoghi di nascita.
Voshart ha ricavato le tonalità scure della pelle dell’imperatore dal Tondo severiano, una pittura a tempera, risalente a circa l’anno 200, realizzata su pannello di legno circolare, che illustra la famiglia di Severo e in cui ha riscontrato una persona di origine nordafricana: l’unico Imperatore di colore. L’apprendimento automatico si è rivelato uno strumento fantastico per rinnovare vecchie foto e video, considerato che riesce a riportare in vita, con effetto fotorealistico, i volti di imperatori romani morti da millenni, semplicemente ripartendo da antiche statue e busti di pietra scheggiata.
Da Daniel Craig a Augusto
Voshart ha anche deciso di aggiungere alcuni “tratti contemporanei” alla ricostruzione. Con lo scopo di aiutare la GAN e aumentare il realismo dei ritratti, talvolta ha inserito nel sistema immagini di celebrità in alta risoluzione. Per esempio, ha usato il volto di Daniel Craig [13] per arrivare al ritratto di Augusto [15].

Dare un volto alle statue, ricostruzione facciale di Settimio Severo, Augusto e Massimino il Trace
Da Andrè the Giant a Massimino il Trace
Per ottenere il ritratto di Massimino il Trace [16] ha inserito immagini del lottatore André The Giant [17], conosciuto al grande pubblico per i suoi ruoli cinematografici. In questo caso, la scelta di usare il volto del lottatore per avvicinarsi all’immagine di Massimino il Trace è dipeso dall’ipotesi che l’imperatore romano avesse avuto in gioventù un disturbo dell’ipofisi che gli aveva procurato una protuberanza mandibolare e una grande statura, proprio come il lottatore contemporaneo.
Ricostruzione facciale, intelligenza artificiale forense.
Èun progetto di 15 volti. Le sculture [17] sono ricostruzioni facciali forensi realizzate a partire da resti non identificati di uomini trovati a BC, in Canada. Voshart ha addestrato le reti neurali sulle foto delle sculture in argilla.
Ogni studente ha trascorso cinque giorni ad applicare l’argilla a teschi stampati in 3D di resti non identificati, come attività all’interno di un seminario. Per questo esperimento, ha eseguito solo l’elaborazione di base della luminosità / contrasto sui 15 volti prima di inserirli nel Generative Adversarial Network (GAN) di Artbreeder [18]. L’obiettivo era incoraggiare le segnalazioni del pubblico nella speranza di favorire il riconoscimento dell’identità di persone scomparse da parte delle famiglie.
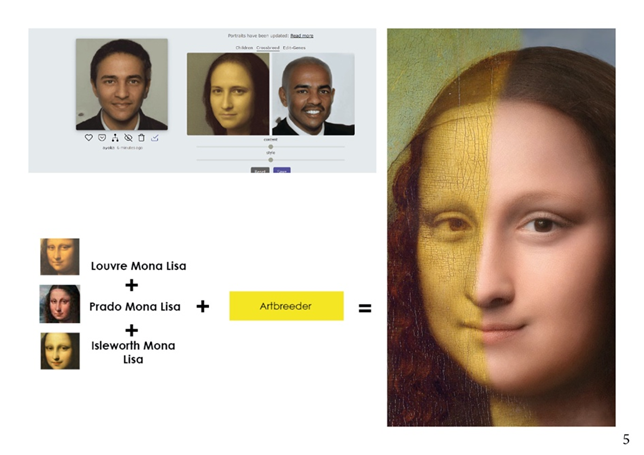
Ricostruzione del volto della Monna Lisa utilizzando le reti neurali
In questo caso Daniel Voshart ha combinato i tre dipinti di Lisa Gherardini, il più famoso ( Louvre Mona Lisa ) e i due meno conosciuti ( Prado Mona Lisa e Isleworth Mona Lisa ) fino a creare un composito sintetico fotorealistico [19].
Artbreeder, lo strumento di rete neurale che ha utilizzato è un software apparentemente semplice ma con risultati difficili da prevedere. Dopo un primo tentativo, assistito dal sistema GAN / rete neurale, non molto buono, Bas Uterwick, un altro creatore di AI Portrait, è riuscito ad ottenere un risultato molto più accurato.
Lo sfondo è una miscela delle versioni del Prado e del Louvre interpretate tramite il nuovo creatore di paesaggi di Artbreeder (v3) che consente di caricare un qualsiasi paesaggio per ottenere un remix, permettendo di raggiungere un giusto compromesso tra realismo e rappresentazione artistica, considerato che il paesaggio di Leonardo da Vinci è immaginario e non basato su un singolo luogo noto.
Artbreeder, sito che presenta GAN addestrate al riconoscimento del volto (esperimento)
La pareidolia ha un ruolo anche nelle GAN?
La capacità dell’intelligenza artificiale di “accrescere la similitudine” è l’equivalente digitale della pareidolia [20].
La pareidolia o illusione pareidolitica è l’illusione subcosciente che tende a ricondurre a forme note oggetti o profili (naturali o artificiali) da una forma casuale. È la tendenza istintiva e automatica a trovare strutture ordinate e forme familiari in immagini disordinate; l’associazione si manifesta in special modo verso le figure e i volti umani. Si ritiene che questa tendenza, che è un caso particolare di apofenia, sia stata favorita dall’evoluzione, poiché consente di individuare situazioni di pericolo anche in presenza di pochi indizi, ad esempio riuscendo a scorgere un predatore mimetizzato.

Pareidolia algoritmica
Deep Dream di Google utilizza lo stesso tipo di rete neurale che alimenta la capacità di Google Foto di identificare le immagini in base al loro contenuto. In sostanza, la rete emula i neuroni nel cervello umano, con un singolo nucleo della rete che si “attiva” ogni volta che vede una parte dell’immagine che pensa di riconoscere.
Gli effetti stravaganti di Deep Dream derivano dal dargli un’immagine iniziale, quindi avviare un ciclo di feedback, in modo che la rete inizi a provare a riconoscere ciò che riconosce. È l’equivalente di chiedere a Deep Dream di disegnare un’immagine di come pensa che sia una nuvola, quindi disegnare un’immagine di come appare la sua immagine, all’infinito.
Le immagini di Deep Dream [21] sono impressionanti perché sembrano quasi alludere all’esistenza di un subconscio della macchina. Basti pensare a uno degli “errori” di interpretazione caratteristici di Deep Dream, la pareidolia, ossia la tendenza della corteccia cerebrale a riportare a forme note immagini o oggetti sconosciuti. Ognuno di questi “errori”, può essere corretto o esasperato. Ma c’è una complicazione: non è possibile osservare i processi interni dell’intelligenza artificiale al lavoro, ma solo i suoi output. È quindi solo attraverso lo studio delle immagini generate e continue modifiche al codice che è possibile personalizzare e direzionare i risultati. È proprio a partire dal processo di apprendimento dei GAN e dei loro malintesi interpretativi che gli artisti hanno cominciato a sperimentare.
La capacità di una rete neurale di riconoscere cosa c’è dentro un’immagine deriva dall’essere addestrati su un set di dati iniziale. Nel caso di Deep Dream, quel set di dati proviene da ImageNet, un database creato dai ricercatori di Stanford e Princeton che hanno costruito un database di 14 milioni di immagini etichettate dall’uomo. Ma Google ha utilizzato un sottoinsieme che conteneva una “classificazione a grana fine” di 120 sottoclassi di cani. In altre parole, Deep Dream di Google vede le facce dei cani ovunque perché è stato addestrato a questo scopo.

Creare Ibridi visivi con un software ‘fai da te’
Artbreeder è un sito online in cui si possono unire due immagini per creare un ibrido [22] in modo da poter sperimentare in prima persona le possibilità dell’IA. in questo campo. L’utente ha la possibilità di scegliere la categoria dell’immagine che desidera generare, può scegliere dal database e combinare tutte le immagini che vuole, mentre i risultati di queste scelte vengono creati con estrema velocità. L’immagine generata si baserà sulle caratteristiche più importanti di ciascuna immagine di input. Il limite di questa app è che non è possibile importare il proprio lavoro e che mette a disposizione un database di immagini di partenza limitato. Ciò può portare a una risultato condizionato più dall’algoritmo che dell’IA.

Quindi può essere considerata vera arte la GAN art?
“Come ci insegna Duchamp, viene esposta nei musei e venduta all’asta: questo le conferisce legittimità e significa che il pubblico umano la sta accettando come tale”.

studentessa dell’ISIA di Roma che a breve conseguirà la laurea triennale in Design del Prodotto.