
di Marco Passarotti*
Abstract
Questo articolo presenta LiLa, una Knowledge Base fondata sui principii del paradigma Linked Data (adottato nel Semantic Web) il cui obiettivo è rendere interoperabili in Rete risorse linguistiche, sia lessicali che testuali, della lingua latina. Dopo un’introduzione dedicata alle diverse fasi metodologiche attraversate lungo la storia della Linguistica Computazionale, l’articolo fornisce una breve panoramica delle risorse linguistiche disponibili per il latino, per poi concentrarsi sull’applicazione dei principii Linked Data ai (meta)dati di tipo linguistico. Viene quindi descritta l’architettura della Knowledge Base LiLa che è mostrata attraverso alcuni esempi specifici del suo uso.
Abstract
This paper introduces the LiLa Knowledge Base, a collection of both lexical and textual resources for Latin made interoperable on the Web by applying the principles of the Linked Data paradigm (widely adopted in the Semantic Web). After discussing the different methodological phases through which Computational Linguistics has passed across its history, the paper presents a brief overview of the currently available linguistic resources for Latin, to focus then on the use of the Linked Data principles for the description of linguistic (meta)data. The architecture of the LiLa Knowledge Base is shown through a number of examples of its use.
Parole chiave
Linguistica Computazionale, Risorse Linguistiche, Latino, Linguistic Linked Open Data, Ontologie
Introduzione
Quando nel 1949 il gesuita trentaseienne Roberto Busa si sedette nello studio del grande capo dell’IBM Thomas Watson Sr. a New York aveva ben chiaro cosa avrebbe voluto realizzare. Si era convinto che i computer, allora enormi macchine rumorose che occupavano intere stanze, avrebbero potuto portare una svolta metodologica nello studio dei testi: la computazione, innanzitutto quantitativa, del dato linguistico avrebbe fornito la documentazione empirica essenziale e oggettiva su cui fondare ogni considerazione di tipo qualitativo.
Busa incontrava Watson con la solidità di chi sente di avere in mano un’intuizione alla base di una rivoluzione inevitabile e assoluta: “se l’idea non fosse venuta a me, sarebbe venuta certamente a qualcun altro”, era solito ripetere padre Busa.
Fu l’inizio di una storia trentennale, che portò alla pubblicazione tra il 1974 e il 1980 dell’Index Thomisticus (Busa, 1974-1980), le concordanze e il corpus lemmatizzato dell’opera omnia di Tommaso d’Aquino: un totale di circa undici milioni di parole.
Nel frattempo, gli studi computazionali sul linguaggio si era andati diffondendo in tutto il mondo. Dopo la presa di coscienza dei limiti della ricerca sulla traduzione automatica, messi nero su bianco dal rapporto ALPAC del 1966 (National Research Council & ALPAC, 1966), la Linguistica Computazionale, che la storia vuole nominata tale proprio dai membri di ALPAC, si era concentrata sullo sviluppo di strumenti di analisi linguistica automatica fondamentale, quali sono la lemmatizzazione (ovvero, la riduzione delle parole di un testo alla loro forma di citazione convenzionale sui dizionari), l’attribuzione delle parti del discorso (come Nome, Verbo e Aggettivo) e dei tratti morfologici (genere, numero, modo, tempo etc.). Insomma, si lavorava affinché i computer potessero realizzare da soli l’analisi grammaticale di un testo.
Parallelamente, la disponibilità di strumenti di analisi linguistica automatica favoriva lo sviluppo di corpora arricchiti con siffatte analisi, ovvero raccolte di testi a cui sono associati diversi livelli di ‘annotazione metalinguistica’: ciascuna parola dei testi è accompagnata dalla sua parte del discorso, dal lemma e, a volte, anche dai tratti morfologici. Strumenti e (meta)dati, dunque: il pane quotidiano di cui si nutre e che produce chi fa Linguistica Computazionale.
A partire dagli anni Novanta del secolo scorso si fa strada il termine “risorse linguistiche”, introdotto dal compianto prof. Antonio Zampolli, fondatore dell’Istituto di Linguistica Computazionale del CNR di Pisa e, giovane, collaboratore di Busa all’Index Thomisticus.
Le “risorse linguistiche” sono raccolte di dati linguistici, macroscopicamente categorizzabili in due tipi: risorse testuali (i corpora, appunto) e risorse lessicali (come i lessici, o i dizionari). Proprio con gli anni Novanta, la crescita progressiva di disponibilità di evidenza empirica di tipo linguistico raccolta in forma di risorse è stata il volàno che, in una sorta di circolo virtuoso, ha portato a una svolta empirista nel trattamento automatico del linguaggio: vengono sviluppati strumenti di tipo probabilistico che fanno machine-learning, ovvero ‘imparano’ regolarità a partire da un insieme di dati di addestramento che consistono, appunto, in corpora testuali (più, o meno annotati). Il circolo è virtuoso in quanto risorse più grandi consentono addestramenti migliori e, quindi, strumenti che forniscono prestazioni più accurate, che, a propria volta, favoriscono lo sviluppo di ulteriori corpora annotati.
La svolta empirista oggi è scoppiata anche alla luce del fatto che viviamo il tempo dei cosiddetti ‘big data’. Siamo circondati dai dati. Quotidianamente vengono prodotti e resi a diverso titolo accessibili in Rete milioni di testi scritti, video e audio, così come d’immagini; una ricerca condotta dalla piattaforma di Business Intelligence Domo nel 2017 ha calcolato che ogni giorno vengono condivise su Snapchat più di 500.000 fotografie, vengono inviate più di 100.000 e-mail di spam, sono pubblicate circa 600 nuove pagine di Wikipedia, Google conduce quasi 4 milioni di ricerche, più di 15 milioni di testi vengono inviati e circa mezzo milione di tweet sono prodotti su Twitter (https://www.domo.com/learn/data-never-sleeps-5?aid=ogsm072517_1&sf100871281=1).
Molti dei dati digitali che sono parte della nostra vita sono di tipo linguistico, comprese queste parole pubblicate su una rivista online. È il paradiso del paradigma empirista, che oggi può facilmente avere a disposizione miliardi di occorrenze di parole sulla cui base addestrare strumenti di trattamento automatico del linguaggio in modalità non supervisionata, ovvero senza neppure il bisogno di arricchire i dati con annotazione metalinguistica (si veda ad esempio la tecnica di machine-learning implementata nel sistema BERT di Google (Tenney at alii, 2019)).
Le risorse linguistiche per il latino
In questa corsa alla realizzazione di risorse linguistiche per le più diverse lingue non è mancata la partecipazione del latino, all’origine della Linguistica Computazionale grazie proprio al lavoro di Busa sui testi di Tommaso d’Aquino. Chiunque si occupi di lingue antiche, infatti, non può prescindere dal quotidiano confronto con i dati testuali, uniche voci che ancora fanno risuonare quelle lingue morte, ovvero ormai prive di parlanti nativi. Per questa ragione, i classicisti sono sempre stati tra coloro che massimamente hanno fatto ricorso a grandi raccolte di testi, in quanto supporti essenziali alla ricerca. Risale agli anni Sessanta l’avvio della realizzazione del corpus elettronico lemmatizzato di testi classici prodotto dal laboratorio LASLA a Liegi (http://web.philo.ulg.ac.be/lasla/), che, solo per il latino, oggi raccoglie più di 130 testi per un totale di circa un milione e settecentomila parole. E dagli anni Ottanta il Packard Humanities Institute (https://packhum.org/texts.html) e la Perseus Digital Library (http://www.perseus.tufts.edu/hopper/) hanno prodotto e messo a disposizione sostanziose raccolte di testi greci e latini in formato digitale, sviluppando contestualmente strumenti di ricerca linguistica che consentissero agli utenti di estrarre facilmente informazione dai dati.
Con gli anni Duemila, la ricerca nel settore si è innanzitutto concentrata sull’arricchimento delle raccolte testuali latine disponibili con livelli di annotazione più “alti” rispetto alla lemmatizzazione e alla morfologia, particolarmente sviluppando ‘treebank’, ovvero corpora annotati a livello sintattico, in cui la sintassi di ogni frase dei testi lì inclusi è rappresentata graficamente in termini di alberi sintattici (‘tree’). Risale al 2006 l’avvio delle prime due treebank della lingua latina, ovvero la Latin Dependency Treebank, che raccoglie testi di epoca classica per un totale di circa 55.000 parole (Bamman & Crane, 2007) e la Index Thomisticus Treebank con più di 500,000 parole (Passarotti, 2019). A queste si sono successivamente aggiunti il corpus PROIEL (Eckhoff et alii, 2018), la Late Latin Charter Treebank (Korkiakangas, 2021) e la raccolta delle opere latine di Dante Alighieri UDante (Cecchini et alii, 2020).
Contemporaneamente al lavoro dedicato allo sviluppo di corpora sintattici per il latino, sono state realizzate anche numerose nuove risorse lessicali digitali, che vanno ad affiancarsi alla lunga tradizione lessicografica delle lingue classiche. Tra esse, meritevoli di menzione sono Latin WordNet (Minozzi, 2017), il lessico morfologico-derivazionale Word Formation Latin (Litta & Passarotti, 2019) e il lessico di valenza Latin Vallex (Passarotti et alii, 2016).
Raccogliere e fare interagire le risorse linguistiche
Tutta questa disponibilità di risorse linguistiche ha sollevato il problema della loro reperibilità e compatibilità. Infatti, che le risorse siano accessibili in luoghi sparsi e in molteplici modalità, oltre che seguano criteri diversi di registrazione dei (meta)dati rappresenta un forte limite al loro utilizzo da parte della comunità scientifica, che incontra numerose difficoltà in fase sia di reperimento che di reciproca interazione tra le risorse.
Ecco, dunque, che, per far fronte a questa difficoltà, ormai da più di un decennio è stata resa disponibile l’infrastruttura CLARIN (www.clarin.eu), che rappresenta un luogo condiviso dove le risorse possono essere pubblicate, indagate e, nella maggior parte dei casi, scaricate, sollevando così gli utenti dalla necessità di cercare i (meta)dati che servono loro nei repository dei diversi sviluppatori e distributori di risorse.
Costituito un luogo comune dove depositare e trovare le risorse linguistiche, la sfida attuale consiste nel farle interagire tra loro, ovvero creare ‘interoperabilità’ tra risorse distribuite sul web. Ad oggi, in CLARIN tale interoperabilità può essere realizzata a livello dei metadati descrittivi delle risorse attraverso la cosiddetta Component MetaData Infrastructure (CMDI) (Broeder et alii, 2022), che raccoglie ‘componenti’, ovvero gruppi di metadati semanticamente coerenti, che vengono connessi a un registro di concetti condiviso (il CLARIN Concept Registry) (Schuurman et alii 2016). Tuttavia, tali concetti non sono (ancora) messi in relazione con quelli di altri schemi/ontologie e, soprattutto, non arrivano a consentire una rappresentazione dei dati più granulari, siano essi lessicali (come, ad esempio, le entrate lessicali dei dizionari) o testuali (le singole parole nei testi).
Una soluzione alla sfida sollevata dall’interoperabilità granulare tra le risorse linguistiche è venuta negli ultimi anni dall’applicazione dei principii del paradigma Linked Data a dati linguistici da parte della dinamica comunità scientifica dei cosiddetti Linguistic Linked Open Data (LLOD), che ha realizzato una serie di ontologie specificamente dedicate alla rappresentazione di informazione (meta)linguistica e un cloud di risorse linguistiche interoperabili in quanto pubblicate in modalità Linked Data (LOD Cloud: https://lod-cloud.net).
Il paradigma Linked Data e la LiLa Knowledge Base
Proprio il latino si trova in una posizione tale da segnare lo stato dell’arte nell’interoperabilità tra le risorse linguistiche in Linked Data. Nel giugno del 2018, infatti, ha preso avvio un progetto finanziato dallo European Research Council (ERC) che ha come obiettivo proprio la realizzazione di una Knowledge Base di risorse latine interoperabili secondo il paradigma Linked Data.
Il progetto, nominato ‘LiLa: Linking Latin’ (https://lila-erc.eu/), che ho l’onore di guidare come Principal Investigator, è attualmente in corso presso il centro di ricerca CIRCSE dell’Università Cattolica del Sacro Cuore di Milano e durerà fino al 2023.
L’architettura della LiLa Knowledge Base è fondata sul ruolo centrale assegnato al lemma, attraverso cui le componenti delle varie risorse linguistiche entrano in reciproca interazione. La Figura 1 la mostra: le risorse lessicali sono costituite da entrate lessicali, che descrivono proprietà di parole; le risorse testuali includono occorrenze di parole in testi (‘token’); gli strumenti di Trattamento Automatico del Linguaggio (TAL; in inglese Natural Language Processing: NLP) producono in output diversi tipi di analisi linguistiche, tra cui anche token (tokenizzatori), che a propria volta sono input di altri strumenti di TAL (come, ad esempio, un parser sintattico). Tutte queste componenti sono rese interoperabili in LiLa attraverso il loro collegamento (‘linking’) a una raccolta di forme di citazione, ovvero lemmi, del latino (chiamata ‘Lemma Bank’) che rappresenta il cuore stesso della Knowledge Base.
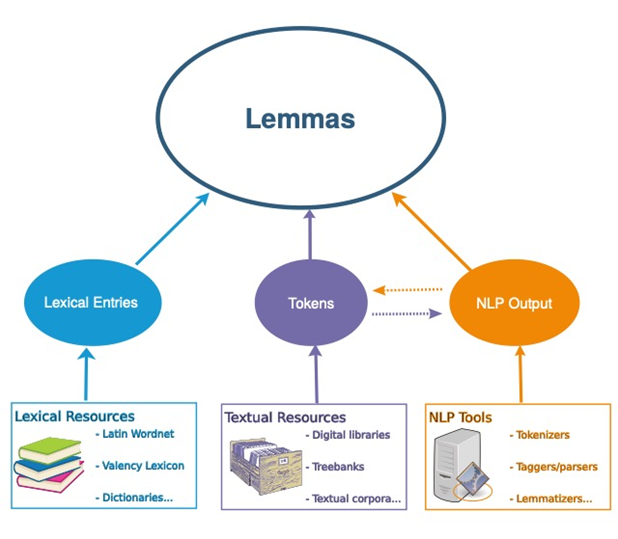
Figura 1. L’architettura fondamentale di LiLa
Attraverso il linking delle diverse risorse linguistiche a LiLa è possibile operare query complesse che fanno uso dei (meta)dati da esse forniti, come cercare in diversi corpora tutte le occorrenze testuali di parole con certe proprietà lessicali, quale ad esempio la presenza di un certo affisso derivazionale registrata nel lessico morfologico-derivazionale Word Formation Latin.
L’interoperabilità tra le risorse sul web in LLOD è resa possibile facendo fronte ai principii del paradigma Linked Data (Berners-Lee, 2006), che stabiliscono di:
- assegnare identificativi unici (URI: Uniform Resource Identifiers) alle ‘cose’ con cui si ha a che fare;
- utilizzare un protocollo di comunicazione come http al fine di consentire di individuare e osservare le ‘cose’;
- utilizzare standard per rappresentare e ricercare le ‘cose’, come RDF (Resource Description Framework) (Lassila & Swick, 1998) e SPARQL (SPARQL Protocol and RDF Query Language) (Prud’Hommeaux & Seaborne, 2008);
- includere link ad altri URI, per consentire di scoprire altre ‘cose’.
Nel caso di LiLa, e più in generale dei LLOD, le ‘cose’ con cui si ha a che fare sono (meta)dati linguistici: parole, parti del discorso, relazioni sintattiche, affissi, morfemi etc. Questi (meta)dati, forniti dalle varie risorse linguistiche, interagiscono tra di loro grazie alla loro rappresentazione attraverso una “lingua” comune, ovvero un vocabolario condiviso che stabilisce quali siano le classi degli oggetti in questione e le relazioni che si possono istituire tra essi. Siffatte descrizioni formali di “ciò che c’è” sono, non a caso, chiamate ‘ontologie’. Le risorse linguistiche in LLOD, dunque, devono essere rappresentate utilizzando ontologie comuni, fondandosi su un modello dei dati comune. Questo modello è RDF, che è incentrato sull’idea di ‘tripla’: il Semantic Web, che è la realizzazione più manifesta del paradigma Linked Data, è costituito da miliardi di triple, ovvero relazioni tra un ‘Soggetto’ e un ‘Oggetto’ attraverso un Predicato, chiamato ‘Proprietà’. Le ontologie stabiliscono quali Proprietà possono connettere quali classi di Soggetti a quali classi di Oggetti. Ad esempio, un Soggetto di una tripla in LiLa può essere un’occorrenza di parola in un testo fornito da un corpus (un ‘token’), che è linkata attraverso una Proprietà definita in un’ontologia (hasLemma) a un Oggetto che è il suo lemma nella Lemma Bank di LiLa.
La Lemma Bank di LiLa è fondata sul vocabolario di OntoLex Lemon (McCrae et alii, 2017), i cui elementi fondamentali sono mostrati dalla Figura 2.
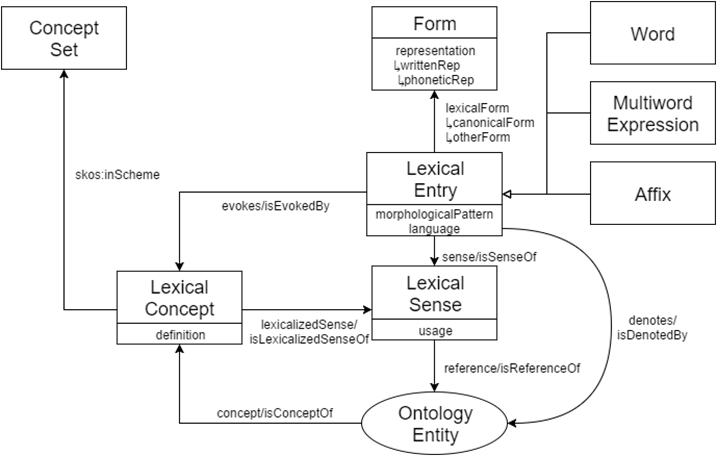
Figura 2. OntoLex Lemon
La Lemma Bank di LiLa è un insieme di individui della classe Form; in particolare, si tratta di Canonical Form, forme di parole convenzionalmente scelte per rappresentare un’entrata lessicale (Lexical Entry), ovvero lemmi.
La Figura 3 mostra alcuni esempi di triple in una visualizzazione a grafo adottata in LiLa sulla base di LodLive (Camarda et alii, 2012), dove i Soggetti e gli Oggetti sono rappresentati in termini di nodi e le Proprietà sono frecce che connettono nodi.
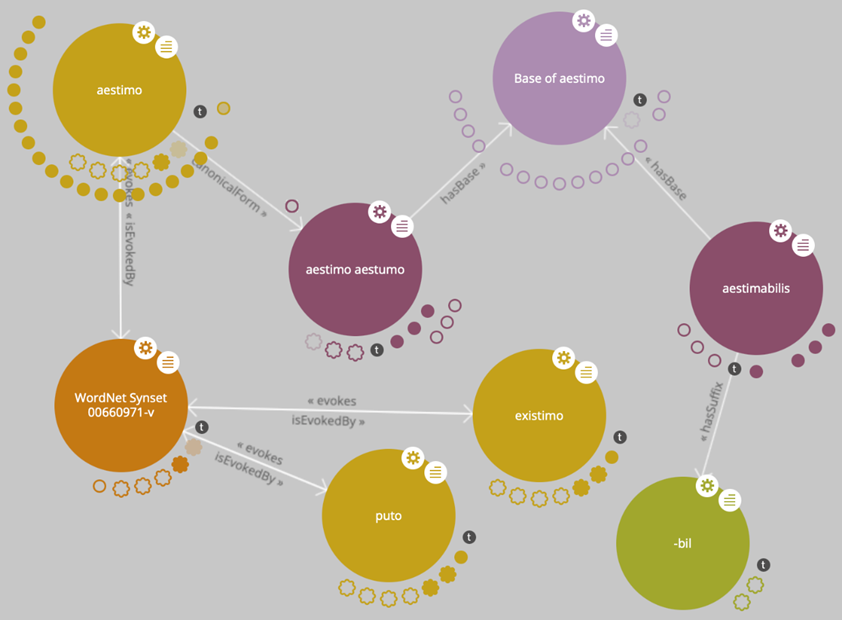
Figura 3. Alcune triple di LiLa
L’immagine riportata in Figura 3 è centrata intorno al nodo per il lemma aestimo (con variante grafica aestumo), che è un individuo della classe Lexical Form di OntoLex Lemon e fa parte della Lemma Bank di LiLa. Questo nodo è linkato, attraverso la Proprietà hasBase, a un nodo nominato (ovvero “che ha label”) “Base of aestimo”, che funge da collettore cui sono connessi tutti i lemmi della Lemma Bank formati con la medesima base lessicale di aestimo, come ad esempio aestimabilis (visibile in Figura 3). Inoltre, ciascun lemma della Lemma Bank che includa uno o più elementi affissali nella propria formazione è linkato ad esso/i: nel caso di aestimabilis, il lemma è linkato tramite la Proprietà hasSuffix al nodo per il suffisso –bil, che a propria volta è collettore di tutti i lemmi della Lemma Bank formati con quell’affisso.
Il nodo di aestimo/aestumo è altresì collegato attraverso la Proprietà canonicalForm di OntoLex Lemon a un individuo della classe Lexical Entry, che è l’entrata lessicale aestimo in una porzione di Latin WordNet controllata manualmente (Franzini et alii, 2019). Tale entrata lessicale è linkata attraverso la Proprietà di OntoLex Lemon evoke (inversamente: isEvokedBy) a un individuo di classe Lexical Concept (del medesimo vocabolario) che consiste nel WordNet synset identificato con il codice 00660971-v nel Princeton WordNet (http://wordnet-rdf.princeton.edu), che ha glossa “estimate the value of”. A questo nodo sono connessi tutti i lemmi della Lemma Bank che lo ‘evocano’: in Figura 3 sono visibili i nodi per i lemmi existimo e puto.
Infine, al nodo di aestimo/aestumo sono linkati i nodi di tutti i token per le occorrenze di quel lemma nei vari corpora testuali inclusi nella Knowledge Base LiLa.
Al momento: le risorse linguistiche per il latino rese interoperabili in LiLa sono le seguenti.
Risorse testuali:
- Index Thomisticus Treebank (https://lila-erc.eu/data/corpora/ITTB/id/corpus), sia nella versione originale che in quella convertita nello schema di annotazione Universal Dependencies (Cecchini et alii, 2018);
- UDante (https://lila-erc.eu/data/corpora/UDante/id/corpus);
- il testo di una breve commedia anonima della tarda antichità dal titolo Querolus sive Aulularia (https://lila-erc.eu/data/corpora/Querolus/id/citationUnit/QuerolussiveAulularia);
- il corpus di testi latini di LASLA (https://lila-erc.eu/data/corpora/Lasla/id/corpus);
Risorse lessicali:
- Word Formation Latin (https://lila-erc.eu/data/lexicalResources/WFL/Lexicon);
- Etymological Dictionary of Latin & the Other Italic Languages (https://lila-erc.eu/data/lexicalResources/BrillEDL/Lexicon) (De Vaan, 2018);
- Latin Vallex (https://lila-erc.eu/data/lexicalResources/LatinVallex/Lexicon);
- Index Graecorum Vocabulorum in Linguam Latinam Translatorum (https://lila-erc.eu/data/lexicalResources/IGVLL/Lexicon): una lista di 1.763 prestiti greci in latino (Franzini et alii, 2020);
- LatinAffectus (https://lila-erc.eu/data/lexicalResources/LatinAffectus/Lexicon): un lessico che assegna un valore di polarità a un insieme di più di 2.500 aggettivi e nomi latini (Sprugnoli et alii, 2020);
- il dizionario bilingue Latino-Inglese curato da Ch.T. Lewis e Ch. Short pubblicato nel 1879 presso Harper and Oxford University Press (https://lila-erc.eu/data/lexicalResources/LewisShort/Lexicon) (Mambrini et alii, 2021).
Presso https://lila-erc.eu/query/ è disponibile un’interfaccia grafica che consente di operare ricerche sulla Knowledge Base a partire dalle entrate della Lemma Bank. La Figura 4 mostra uno screenshot dell’interfaccia che presenta il risultato di una query che cerca le entrate della Lemma Bank che hanno lemma=aestimo e pos=verb (pos: part of speech). Nella parte bassa della Figura è presentato l’unico lemma corrispondente ai criteri di query. Sulla riga dell’output relativo a aestimo, oltre al nome del lemma e alla sua parte del discorso sono riportate alcune icone. Un gruppo di quattro icone indica le risorse lessicali in cui è presente il lemma in questione: nell’ordine, Word Formation Latin, il dizionario di Lewis & Short, Latin WordNet e il dizionario etimologico di De Vaan. Cliccando su una di queste icone, vengono mostrati i contenuti dell’entrata lessicale nella risorsa in questione. L’icona rettangolare con tre righe è un link al datasheet del lemma, ovvero una pagina che riassume le triple del Soggetto (in questo caso, il lemma aestimo, ovvero l’individuo con URI https://lila-erc.eu/data/id/lemma/87940). Infine, l’icona costituita da tre piccole palle rimanda alla visualizzazione LodLive del nodo del lemma aestimo.
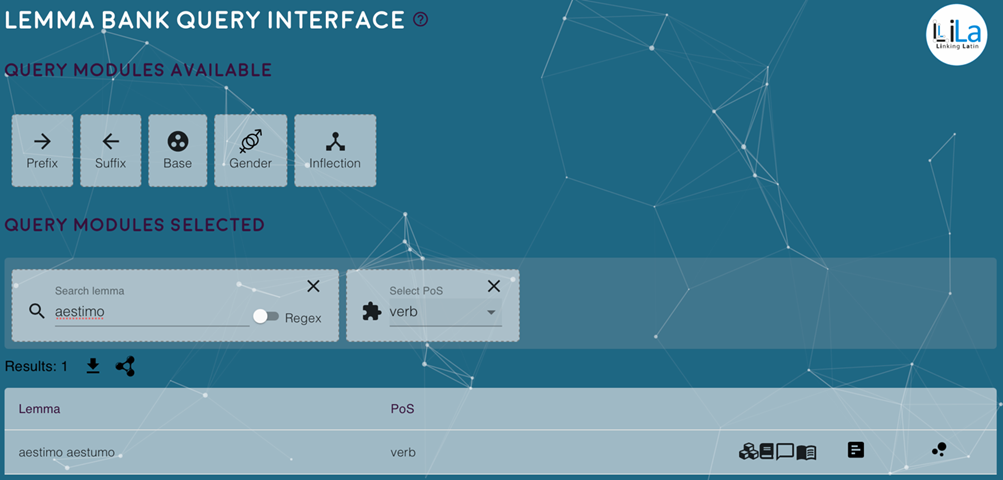
Figura 4. L’interfaccia di query della Lemma Bank di LiLa
Un altro servizio di LiLa è l’endpoint presso cui comporre e lanciare query SPARQL sulla Knowledge Base (https://lila-erc.eu/sparql/). Una serie di query precompilate è messa a disposizione degli utenti che non avessero dimestichezza con il linguaggio SPARQL.
Conclusioni
Dopo essersi concentrata per decenni sullo sviluppo di raccolte di dati linguistici lessicali e testuali, oltre che di strumenti per analizzarli automaticamente, alla svolta del nuovo millennio la ricerca di area linguistico-computazionale si è trovata davanti alla sfida, ineludibile, di valorizzare al meglio questa massa di (meta)dati, non solo in quanto essenziale supporto all’addestramento di strumenti di TAL in modalità machine-learning, ma anche come documentazione a fondamento di ricerche linguistico-teoriche empiricamente motivate.
Ad oggi, l’approccio che sembra essere più promettente perché tale valorizzazione si realizzi pienamente consiste nello sviluppo di un ecosistema condiviso e aperto (ovvero, accessibile ed estendibile) in cui i (meta)dati delle risorse linguistiche possano interagire, fornendo agli utenti la possibilità di combinarli secondo esigenza.
Applicare i principii del paradigma Linked Data alle risorse linguistiche è il modo su cui la ricerca sta attualmente lavorando per portare a compimento un siffatto ecosistema interoperabile. Si tratta di un esempio, auspicabilmente virtuoso, di interdisciplinarità: un paradigma sviluppato originariamente per mettere in atto gli obiettivi del Semantic Web è applicato a (meta)dati linguistici e, nello specifico, a testi e lessici latini. Il naturale e intimo rapporto che gli studi classici mantengono con l’evidenza testuale è la ragione di fondo che spinge e motiva questa interdisciplinarità: come il latino è stata una delle prime lingue trattate a computer, grazie ai lavori di padre Busa, così oggi il latino è la lingua che può vantare il più granulare livello di interoperabilità tra le sue risorse grazie alla LiLa Knowledge Base, che consente l’interazione a livello della singola occorrenza di parola e della singola entrata lessicale.
L’obiettivo più prossimo è fare vivere davvero LiLa, portando le risorse digitali, gli strumenti computazionali di analisi linguistica e la loro interoperabilità sul tavolo di lavoro quotidiano del classicista: è un’ulteriore sfida, che riguarda non solo la ricerca, ma anche, e forse soprattutto, la formazione alla ricerca. Non sarà banale affrontarla, dato un certo grado di conservatorismo riottoso non infrequente nel mondo degli studi classici: ma è inevitabile.
Ringraziamenti
Il progetto “LiLa: Linking Latin” è finanziato dallo European Research Council (ERC) nell’ambito del programma Horizon 2020 – Grant Agreement N. 769994.
Bibliografia
Bamman, D. & Crane, G. (2007), The Latin Dependency Treebank in a cultural heritage digital library, in Sporleder, C., van den Bosch, A. & Grover, C. (eds.), Proceedings of the Workshop on Language Technology for Cultural Heritage Data (LaTeCH 2007) (33-40), Prague: Association for Computational Linguistics.
Berners-Lee, T. (2006), Linked Data, https://www.w3.org/DesignIssues/LinkedData.html.
Broeder, D., Windhouwer, M., Van Uytvanck, D., Goosen, T. & Trippel, T. (2022), CMDI: a component metadata infrastructure, in Arranz, V., Broeder, D., Gaiffe, B., Gavrilidou, M., Monachini, M. & Trippel, T. (eds.), Proceedings of the Workshop “Describing language resources with metadata: towards flexibility and interoperability in the documentation of language resources” (1-4), Paris: European Language Resources Association.
Busa, R. (1974-1980), Index Thomisticus, Stuttgart-Bad Cannstatt: Frommann-Holzboog.
Camarda, D.V., Mazzini, S. & Antonuccio, A. (2012), LodLive, exploring the web of data, in Sack, H., Pellegrini, T., Presutti, V. & Pinto, H.S. (eds.), Proceedings of the 8th International Conference on Semantic Systems (197-200), New York: Association for Computing Machinery.
Cecchini, F.M., Passarotti, M., Marongiu, P. & Zeman, D. (2018), Challenges in converting the Index Thomisticus treebank into universal dependencies, in De Marneffe, M.C., Lynn, T. & Schuster, S. (eds.), Proceedings of the Second Workshop on Universal Dependencies (UDW 2018) (27-36), Bruxelles: Association for Computational Linguistics.
Cecchini, F.M., Sprugnoli, R., Moretti, G. & Passarotti, M. (2020), UDante: First Steps Towards the Universal Dependencies Treebank of Dante’s Latin Works, in Monti, J., Dell’Orletta, F. & Tamburini, F. (eds.), Proceedings of the Seventh Italian Conference on Computational Linguistics (1-7), Bologna: CEUR Workshop Proceedings.
De Vaan, M. (2008), Etymological dictionary of Latin and the other Italic languages, Boston-Leiden: Brill.
Eckhoff, H., Bech, K., Bouma, G., Eide, K., Haug, D., Haugen, O.E. & Jøhndal, M. (2018), The PROIEL treebank family: a standard for early attestations of Indo-European languages, “Language Resources and Evaluation”, 52(1), 29-65.
Franzini, G., Peverelli, A., Ruffolo, P., Passarotti, M., Sanna, H., Signoroni, E., Venturi, V. & Zampedri, F. (2019), Nunc Est Aestimandum: Towards an Evaluation of the Latin WordNet, in Bernardi, R., Navigli, R. & Semeraro, G. (eds.), Proceedings of the Sixth Italian Conference on Computational Linguistics (1-8), Bari: CEUR Workshop Proceedings.
Korkiakangas, T. (2021), Late Latin Charter Treebank: contents and annotation, “Corpora”, 16(2), 191-203.
Lassila, O & Swick, R.R. (1998), Resource description framework (RDF) model and syntax specification, http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.44.6030.
Litta, E. & Passarotti, M. (2019), (When) inflection needs derivation: a word formation lexicon for Latin, in Holmes, N., Ottink, M., Schrickx, J. & Selig, M. (eds.), Lemmata Linguistica Latina. Volume I: Words and Sounds (224-239), Berlin-Boston: Walter de Gruyter GmbH.
Mambrini, F., Litta, E., Passarotti, M. & Ruffolo, P. (2021), Linking the Lewis & Short Dictionary to the LiLa Knowledge Base of Interoperable Linguistic Resources for Latin, in Fersini, E., Passarotti, M. & Patti, V. (eds.), Proceedings of the Eighth Italian Conference on Computational Linguistics (1-7), Milano: CEUR Workshop Proceedings.
McCrae, J.P., Bosque-Gil, J., Gracia, J., Buitelaar, P. & Cimiano, P. (2017), The Ontolex-Lemon model: development and applications, in Kosem, I., Tiberius, C., Jakubicek, M., Kallas, J., Krek, S. & Baisa, V. (eds.), Proceedings of eLex 2017 conference (19-21), Brno: Lexical Computing CZ s.r.o.
Minozzi, S. (2017), Latin WordNet, una rete di conoscenza semantica per il latino e alcune ipotesi di utilizzo nel campo dell’Information Retrieval, in Mastandrea, P. (a cura di), Strumenti digitali e collaborativi per le Scienze dell’Antichita (123-134), Venezia: Edizioni Ca’ Foscari.
National Research Council (US). Automatic Language Processing Advisory Committee & ALPAC (1966), Language and Machines: Computers in Translation and Linguistics; a Report (Vol. 1416), National Academies.
Passarotti, M. (2019), The Project of the Index Thomisticus Treebank, in Berti, M. (ed.), Digital Classical Philology. Vol. 10 of Age of Access? Grundfragen der Informationsgesellschaft (299-320), Berlin-Boston: Walter de Gruyter GmbH.
Passarotti, M., Saavedra, B.G. & Onambele, C. (2016), Latin vallex. a treebank-based semantic valency lexicon for Latin, in Calzolari, N., Choukri, K., Declerck, T., Grobelnik, M., Maegaard, B., Mariani, J., Moreno, A., Odijk, J. & Piperidis, S. (eds.), Proceedings of the Tenth International Conference on Language Resources and Evaluation (2599-2606), Paris: European Language Resources Association.
Prud’Hommeaux, E. & Seaborne, A. (2008), SPARQL Query Language for RDF. W3C, https://www.w3.org/TR/rdf-sparql-query/
Schuurman, I., Windhouwer, M., Ohren, O. & Zeman, D. (2016), CLARIN concept registry: the new semantic registry, in De Smedt, K. (ed.), Selected Papers from the CLARIN Annual Conference 2015 (62-70), Linköping: Linköping University Electronic Press.
Sprugnoli, R., Passarotti, M., Corbetta, D. & Peverelli, A. (2020), Odi et Amo. Creating, Evaluating and Extending Sentiment Lexicons for Latin, in Calzolari, N., Béchet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., Mazo, H., Moreno, A., Odijk, J. & Piperidis, S. (eds.), Proceedings of the Twelfth International Conference on Language Resources and Evaluation (3078-3086), Paris: European Language Resources Association.
Tenney, I., Dipanjan, D. & Pavlick, E. (2019), BERT Rediscovers the Classical NLP Pipeline, in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (4593-4601), Florence: Association for Computational Linguistics.

* Marco Passarotti è Professore Ordinario di Glottologia e Linguistica presso l’Università Cattolica del Sacro Cuore di Milano. I suoi interessi di ricerca si concentrano sulla Linguistica Computazionale e, nello specifico, sullo sviluppo, l’uso e la distribuzione d risorse linguistiche e strumenti di trattamento automatico della lingua latina. Dal 2006 guida il progetto della Index Thomisticus Treebank. Nel 2009 ha fondato il centro di ricerca CIRCSE, di cui è attualmente Direttore. Dal 2018 è Principal Investigator di un ERC-Consolidator Grant (LiLa: Linking Latin).